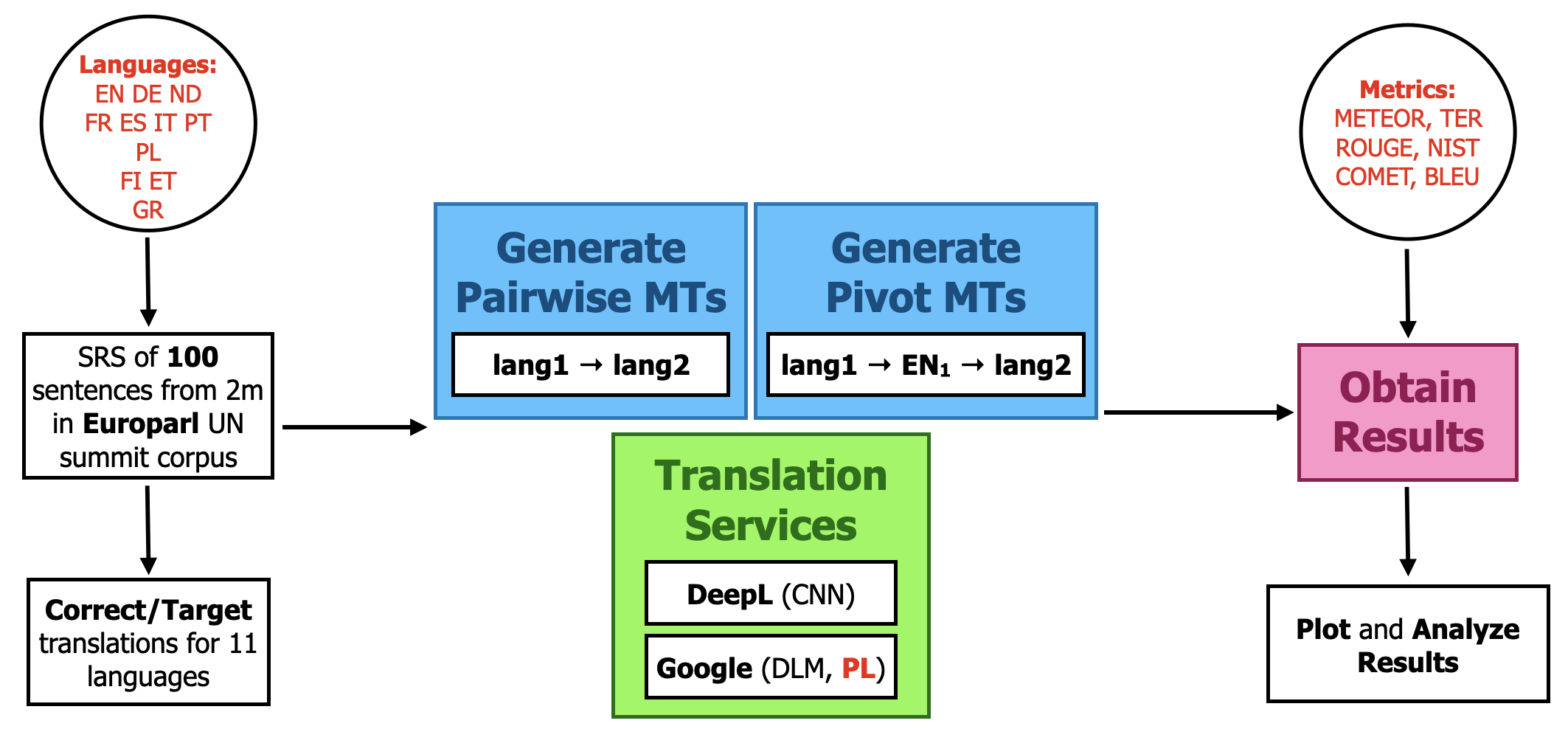
We start by selecting 11 languages, with some language families and isolates to assess whether
languages' being in the same family correlate with improvements with MT performance. These were:
Germanic: English (EN), German (DE), Dutch (NL)
Romance: French (FR), Spanish (ES), Italian (IT), Portuguese (PT)
Finno-Ugric: Finnish (FI), Estonian (ET)
Polish (PL) (note that Polish is west Slavic and not an isolate, but for our project, it was lonely)
Greek (EL or GR)
There's a well-known European corpus for language translation, Europarl, which contains nearly 2 million sentences between English and many European languages. This is a corpus of EU Parliament spoken sentences and includes all 11 of our languages. We use this corpus to translate all 11 * 10 = 110 combinations for our project; it also provides us the necessary control variable.
100 sentences common between all languages are selected from a simple random sample of the corpus. The task now splits into two parts: Pairwise Translations, and Pivot Translations.
Pairwise Translations: For each language pair A and B, translations (through DeepL and GT) are performed between A → B and B → A. We translate a total of 110 combinations.
Pivot Translations: English is the pivot language. For each language pair A and B (with A and B both non-English), translations (through DeepL and GT) are performed thus. First, translate from A into English. Then, translate from English to B. Note that we already have the "A → EN" results, as they were performed during pairwise translation. However, the "EN → B" component is new, as the "EN", or, more accurately, the "EN(A)" (because the English generated by translation from language A is characteristic of A), is 'new' and not the same English as "EN" in our pairwise translations. Thus, we need to translate a total of 10 * 9 = 90 new combinations: for each of the 10 non-English languages, 9 translations from "EN(A)" to the possible B's.
Translation accuracies are subsequently measured through 6 metrics: BLEU, COMET, METEOR, NIST, ROUGE, and TER ("Translation Error Rate"; unlike the other 5 metrics, less is better). Results can be plotted as 2-d heatmaps, with "from language" and "to language" as the axes.
To summarize: We have two primary independent variables: the languages to translate from and to. The other independent variables are: the MT system (DeepL or GT), the metric (one of the 6), and the type of translation (pairwise or pivot). The control is the common Europarl corpus.
The full pipeline is depicted below.