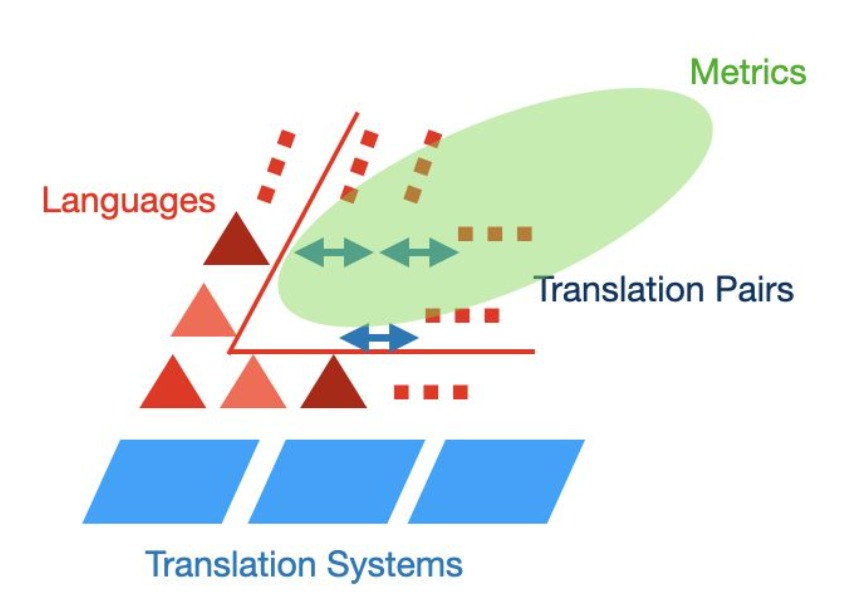
There are two paths we could take from here: Scale up our existing project, or perform a new project.
With respect to the former, there are three main ways to do so. We can incorporate more languages, particularly non-European (e.g. Chinese); use a wider range of text documents (though finding corpora is not easy); or use more translation systems (Yandex, Baidu, Microsoft).
We could also perform the following "reverse" task. Given language B, and a translation into language B, predict which language A the translation came from. This is similar to "given an audio of English speech, predict the speaker's native language".
This page will be updated as we finalize our paper and code!